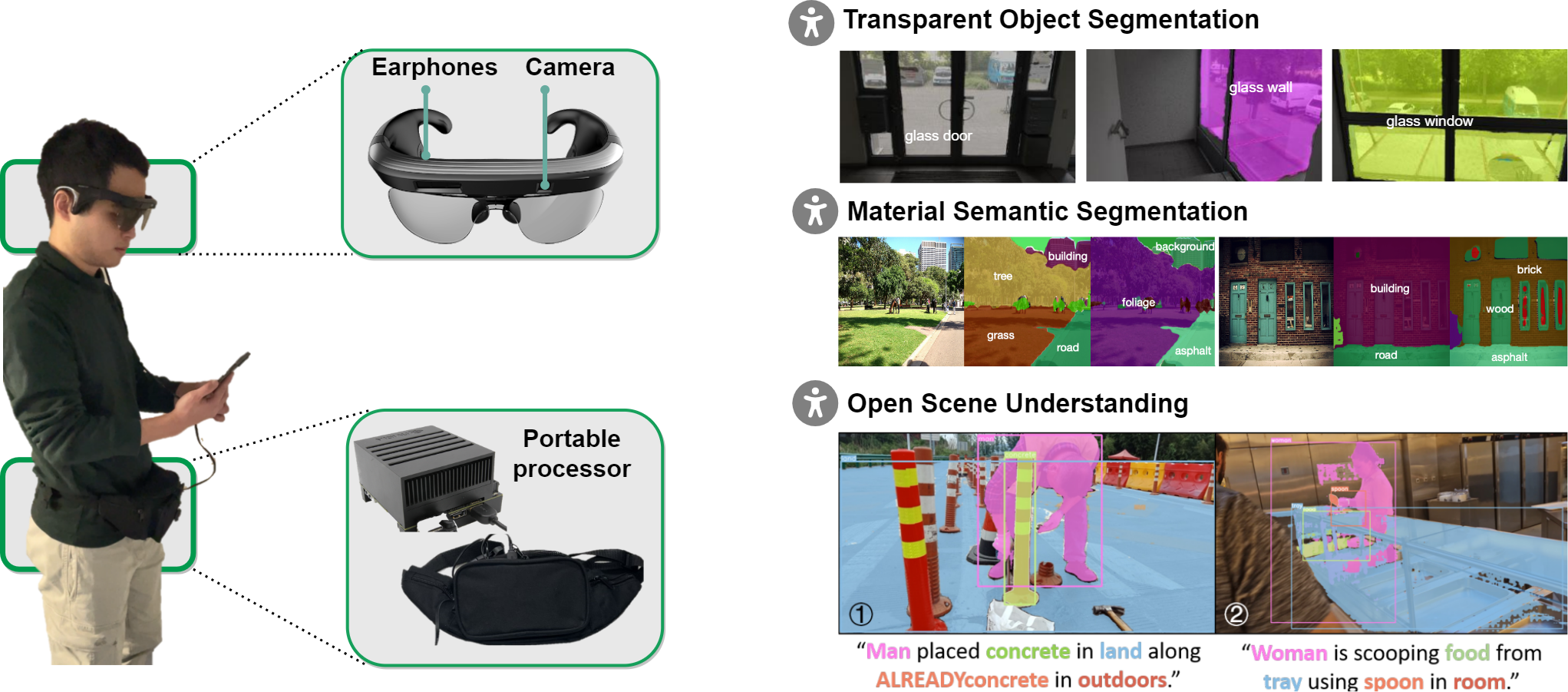
Vision4Blind system can be used for transparent object segmentation, material semantic segmentation, open scene understanding, and more.
|
|
|
|
|
|
|
|
|
Vision4Blind system can be used for transparent object segmentation, material semantic segmentation, open scene understanding, and more. |
|
|
Transparent objects, such as glass walls and doors, constitute architectural obstacles hindering the mobility of people with low vision or blindness. For instance, the open space behind glass doors is inaccessible and the cups in glass shelves are unreachable, unless they are correctly perceived and interacted with. To address that, we build a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) perception model, which can segment general- and transparent objects. The two dense segmentation results are further combined with depth information in the system to help users navigate safely and assist them to negotiate transparent obstacles. The entire Trans4Trans model is constructed in a symmetrical encoder-decoder architecture, which outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets, obtaining mIoU of 45.13% and 75.14%, respectively. Through a user study and various pre-tests conducted in indoor and outdoor scenes, the usability and reliability of our assistive system have been verified.
Associated Paper:
Trans4Trans: Efficient Transformer for Transparent Object Segmentation to Help Visually Impaired People Navigate in the Real World, [pdf], [code].
Wearable robotics can improve the lives of People with Visual Impairments (PVI) by providing additional sensory information. Blind people typically recognize objects through haptic perception. However, knowing materials before touching is under-explored in the field of assistive technology. To fill this gap, in this work, a wearable robotic system, MATERobot, is established for PVI to recognize materials before hand. Specially, the human-centric system can perform pixel-wise semantic segmentation of objects and materials. Considering both general object segmentation and material segmentation, an efficient MateViT architecture with Learnable Importance Sampling (LIS) and Multi-gate Mixture-of-Experts (MMoE) is proposed to wearable robots to achieve complementary gains from different target domains. Our methods achieve respective 40.2% and 51.1% of mIoU on COCOStuff and DMS datasets, surpassing previous method with +5.7% and +7.0% gains. Moreover, on the field test with participants, our wearable system obtains a score of 28 in NASA-Task Load Index, indicating low cognitive demands and ease of use. Our MATERobot demonstrates the feasibility of recognizing material properties through visual cues, and offers a promising step towards improving the functionality of wearable robots for PVI.
Associated Paper:
MATERobot: Material Recognition in Wearable Robotics for People with Visual Impairments, [pdf], [code].
Grounded Situation Recognition (GSR) is capable of recognizing and interpreting visual scenes in a contextually intuitive way, yielding salient activities (verbs) and the involved entities (roles) depicted in images. In this work, we focus on the application of GSR in assisting people with visual impairments (PVI). However, precise localization information of detected objects is often required to navigate their surroundings confidently and make informed decisions. For the first time, we propose an Open Scene Understanding (OpenSU) system that aims to generate pixel-wise dense segmentation masks of involved entities instead of bounding boxes. Specifically, we build our OpenSU system on top of GSR by additionally adopting an efficient Segment Anything Model (SAM). Furthermore, to enhance the feature extraction and interaction between the encoder-decoder structure, we construct our OpenSU system using a solid pure transformer backbone to improve the performance of GSR. In quantitative analysis, our model achieves state-of-the-art performance on the SWiG dataset. Moreover, through field testing on dedicated assistive technology datasets and application demonstrations, the proposed OpenSU system can be used to enhance scene understanding and facilitate the independent mobility of people with visual impairments.
Associated Paper:
Open Scene Understanding: Grounded Situation Recognition Meets Segment Anything for Helping People with Visual Impairments, [pdf], [code].
 |
 |