Delivering Arbitrary-Modal Semantic Segmentation
(CVPR 2023)
|
Karlsruhe Institute of Technology
|
Hunan University
|
Zhejiang University
|
Beihang University
|
|
|
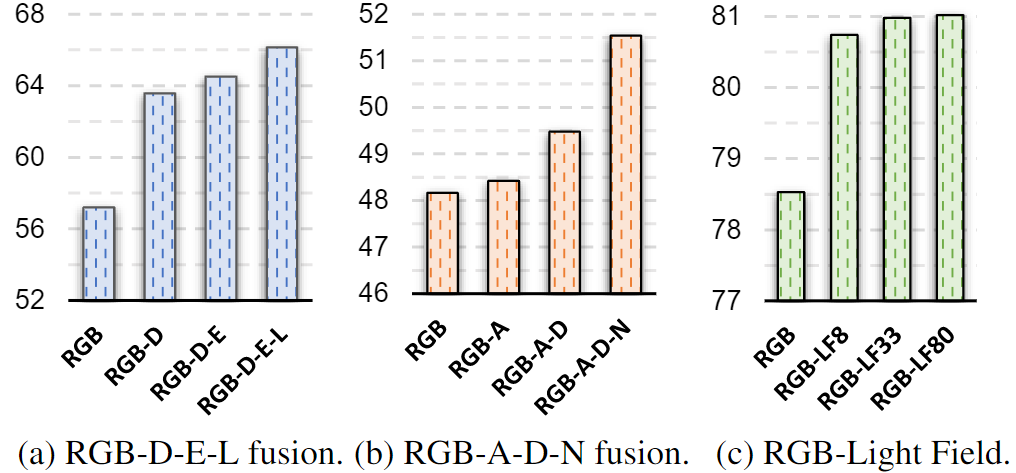
Fig. 1: Arbitrary-modal semantic segmentation results of CMNeXt.
|
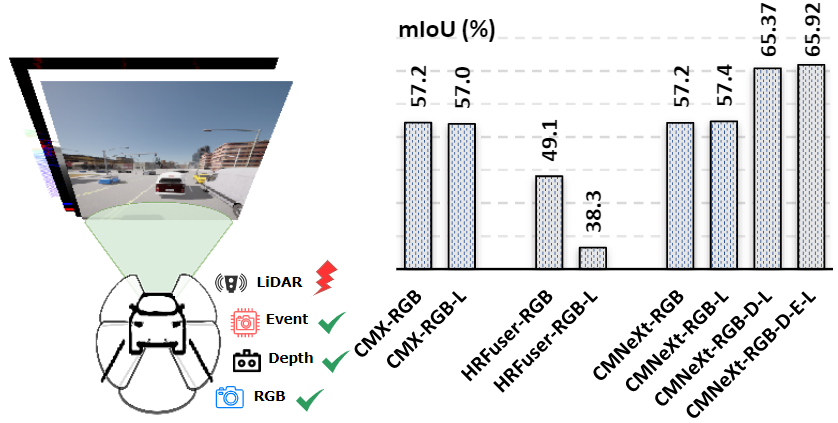
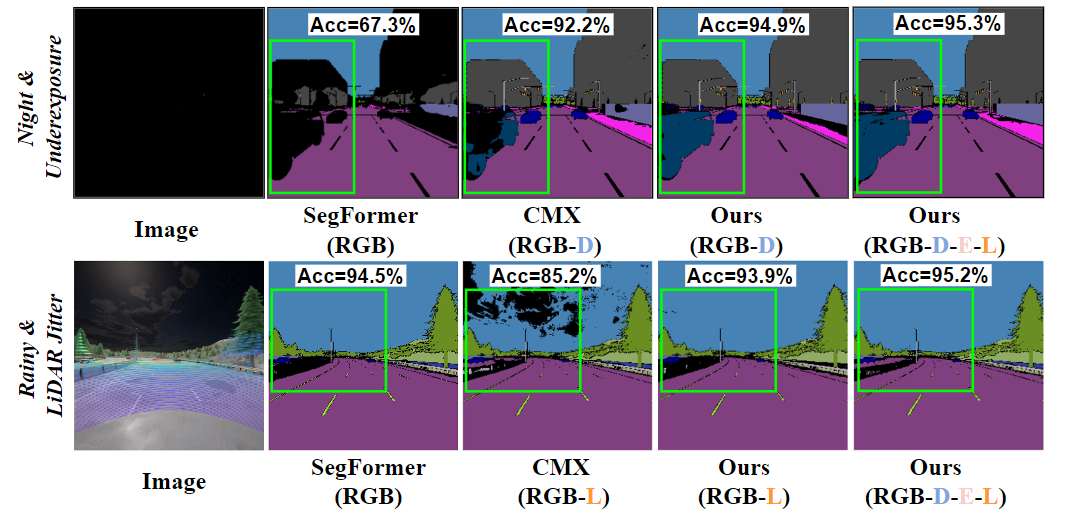
Fig. 2: Comparison if sensor failure (i.e., LiDAR Jitter).
|
Abstract
Multimodal fusion can make semantic segmentation more robust. However, fusing an arbitrary number of
modalities remains underexplored. To delve into this problem, we create the DeLiVER arbitrary-modal
segmentation benchmark, covering Depth, LiDAR, multiple Views, Events, and RGB. Aside from this, we
provide this dataset in four severe weather conditions as well as five sensor failure cases to exploit modal
complementarity and resolve partial outages. To facilitate this data, we present the arbitrary cross-modal
segmentation model CMNeXt. It encompasses a Self-Query Hub (SQ-Hub) designed to extract effective
information from any modality for subsequent fusion with the RGB representation and adds only negligible
amounts of parameters (~0.01M) per additional modality. On top, to efficiently and flexibly harvest
discriminative cues from the auxiliary modalities, we introduce the simple Parallel Pooling Mixer (PPX). With
extensive experiments on a total of six benchmarks, our CMNeXt achieves state-of-the-art performance,
allowing to scale from 1 to 80 modalities on the DeLiVER, KITTI-360, MFNet, NYU Depth V2, UrbanLF, and
MCubeS datasets. On the freshly collected DeLiVER, the quad-modal CMNeXt reaches up to 66.30% in mIoU
with a +9.10% gain as compared to the mono-modal baseline.
DeLiVER Dataset
Dataset statistic
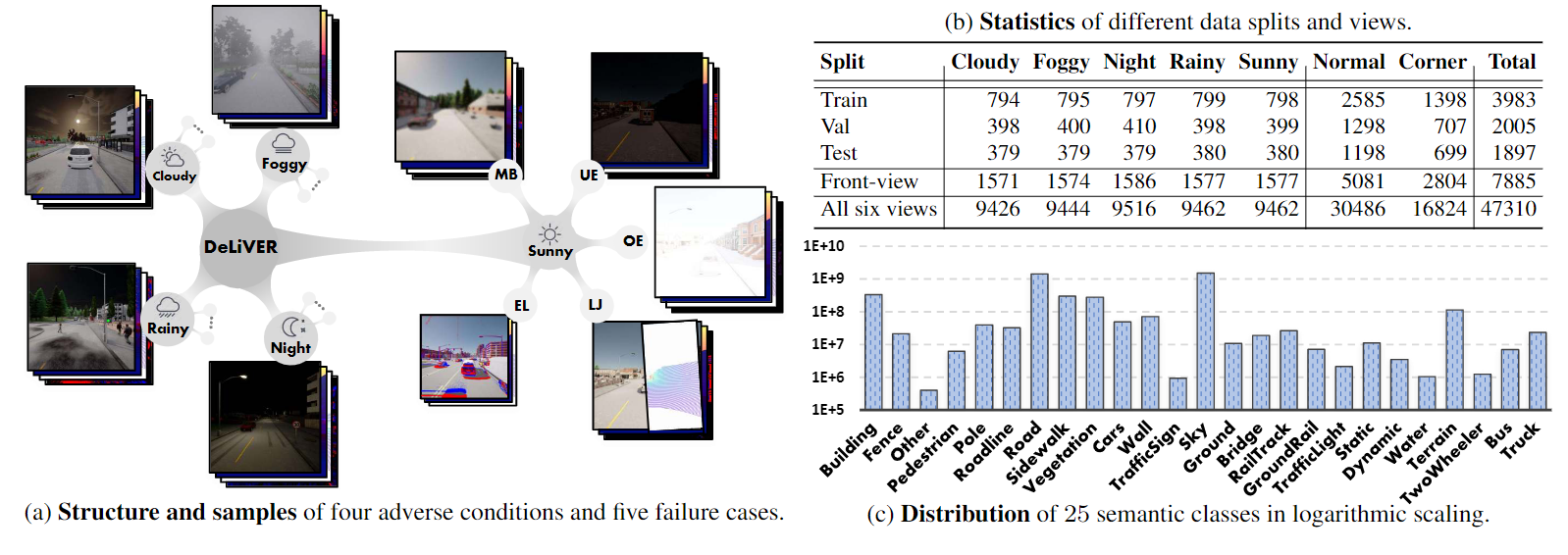
DeLiVER multimodal dataset including (a) four adverse conditions out of five conditions(cloudy, foggy, night-time, rainy and sunny).
Apart from normal cases, each condition has five corner cases (MB: Motion Blur; OE: Over-Exposure; UE: Under-Exposure; LJ: LiDAR-Jitter; and EL: Event Low-resolution).
Each sample has six views. Each view has four modalities and two labels (semantic and instance). (b) is the data statistics. (c) is the data distribution of 25 semantic classes.
Dataset structure
Four adverse road scene conditions of rainy, sunny, foggy, and night are included in our dataset.
There are five sensor failure cases including Motion Blur (MB), Over-Exposure (OE), Under-Exposure (UE), LiDAR-Jitter (LJ), and
Event Low-resolution (EL) to verify that the performance of model is robust and stable in the presence of sensor failures. The sensors are mounted at
different locations on the ego car to provide multiple views including front, rear, left, right, up, and down.
Each sample is annotated with semantic and instance labels. In this work, we focus on the front-view semantic segmentation.
|
The 25 semantic classes are: Building, Fence, Other, Pedestrian, Pole, RoadLine, Road, SideWalk, Vegetation, Cars, Wall, TrafficSign, Sky, Ground, Bridge, RailTrack, GroundRail, TrafficLight, Static, Dynamic, Water, Terrain, TwoWheeler, Bus, Truck.
CMNeXt Model
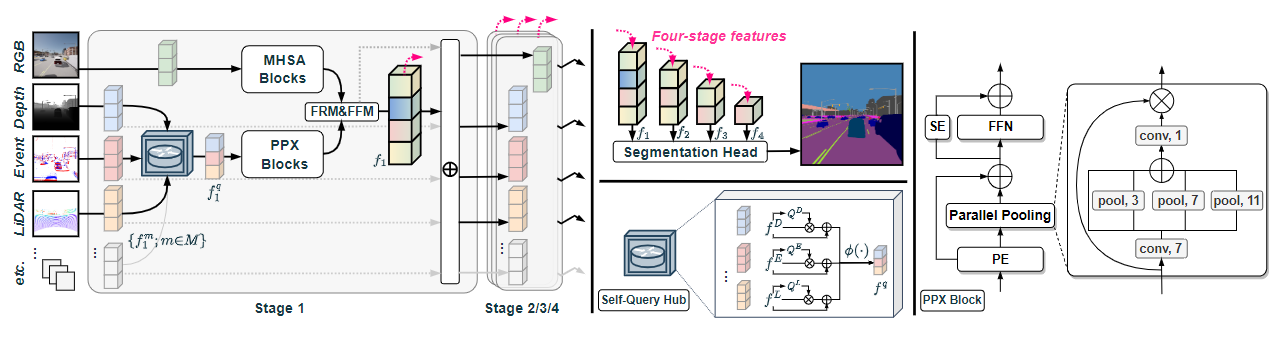
CMNeXt architecture in Hub2Fuse paradigm and asymmetric branches, having e.g., Multi-Head Self-Attention (MHSA) blocks
in the RGB branch and our Parallel Pooling Mixer (PPX) blocks in the accompanying branch. At the hub
step, the Self-Query Hub selects informative features from the supplementary modalities. At the fusion
step, the feature rectification module (FRM) and feature fusion module (FFM) are used for feature fusion.
Between stages, features of each modality are restored via adding the fused feature. The four-stage fused
features are forwarded to the segmentation head for the final prediction.
Visualization
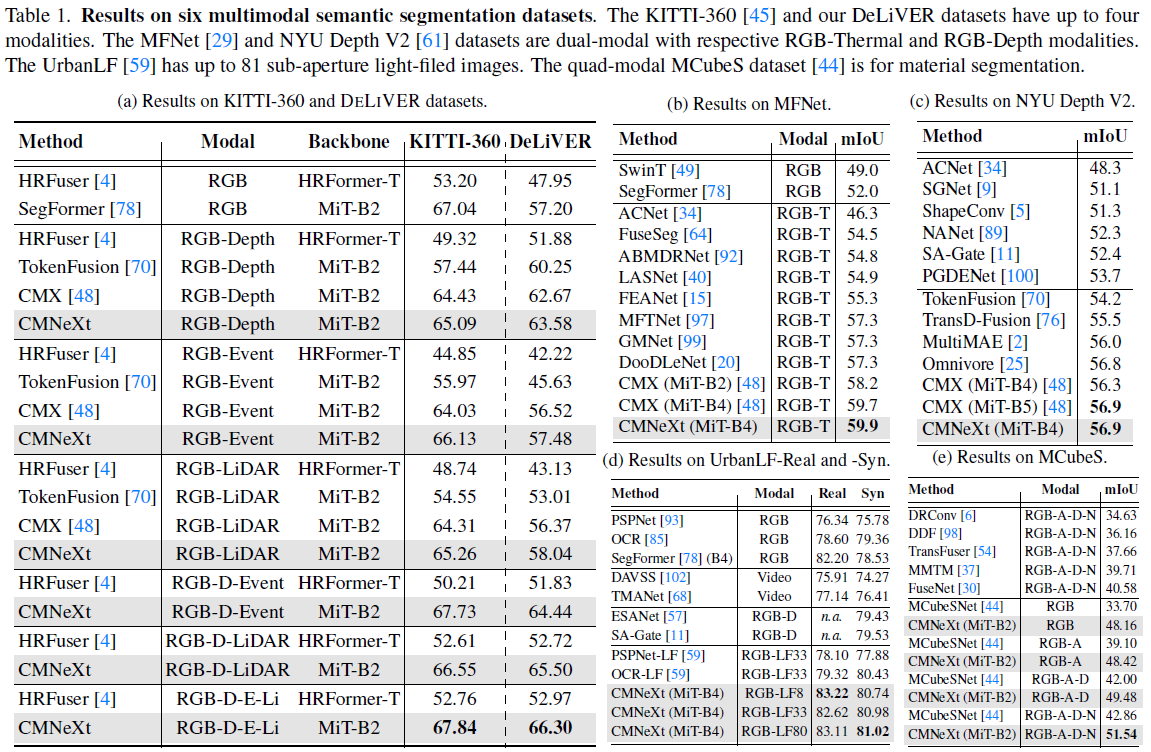
Experiment Result
Citation
|
If you find our work useful in your research, please cite:
@inproceedings{zhang2023delivering,
title={Delivering Arbitrary-Modal Semantic Segmentation},
author={Zhang, Jiaming and Liu, Ruiping and Shi, Hao and Yang, Kailun and Rei{\ss}, Simon and Peng, Kunyu and Fu, Haodong and Wang, Kaiwei and Stiefelhagen, Rainer},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={1136--1147},
year={2023}
}
|